[파이썬/머신러닝] 사이킷런 기초 다지기 - 2
[파이썬/머신러닝] 사이킷런 기초 다지기 - 2
2. 사이킷런의 기반 프레임워크 익히기
- 사이킷런은 머신러닝 모델학습을 위해서 fit()을, 학습된 모델의 예측을 위해 predict() 메소드를 제공합니다.
- 분류 알고리즘을 구현한 클래스를 Classifier로, 회귀 알고리즘을 구현한 클래스를 Regressor로 지칭합니다. 이 둘을 합쳐서 Estimator 클래스 라고 부릅니다.
✔ 지도 학습의 모든 알고리즘을 구현한 클래스를 통칭해 Estimator라고 부르고 이 클래스는 fit()와 predict()를 내부에서 구현하고 있습니다.
✔ 일반적으로 머신러닝 모델을 구축하는 주요 프로세스는 피처의 가공, 추출을 수행하는 피처처리(feature processing), ML 알고리즘 학습/예측 수행 모델평가의 단계를 반복적으로 수행하는 것입니다.
2-1. 내장된 예제 데이터 세트
사이킷런에는 외부 웹사이트에서 다운 받을 필요 없이 예제로 활용할 수 있는 좋은 데이터 세트가 내장되어 있습니다.
- datasets.load_boston() : 회귀 용도, 미국 보스턴의 집 피처들과 가격에 대한 데이터 세트
- datasets.load_breast_cancer() : 분류 용도. 위스콘신 유방암 피처들과 악성/음성 레이블 데이터 세트
- datasets.load_diabetes() : 회귀 용도. 당뇨 데이터 세트
- datasets.load_digits() : 분류 용도. 0~9까지 숫자의 이미지 픽셀 데이터 세트
- datasets.load_iris() : 분류 용도. 붓꽃 데이터 피처를 가진 데이터 세트
✔ 사이킷런에 내장된 이 데이터 세트는 일반적으로 딕셔너리 형태로 되어 있습니다. 키는 보통 data, target, target_name, feature_names. DESCR로 구성돼 있습니다.
from sklearn.datasets import load_iris
iris_data = load_iris()
keys = iris_data.keys()
print(keys)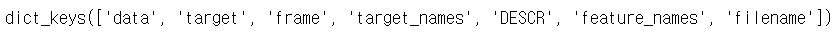
✔ 붓꽃 데이터 세트가 가지고 있는 키 값들을 출력한 결과 입니다.
from sklearn.datasets import load_iris
iris_data = load_iris()
keys = iris_data.keys()
#print(keys)
print('feature_names : \n' , iris_data.feature_names)
print('target_names : \n' , iris_data.target_names)
print('data : \n' , iris_data['data'])
print('target : \n' , iris_data.target)

✔ 붓꽃 데이터 세트가 가지고 있는 키가 가리키는 값을 출력한 결과 입니다.
3. Model Selection 모듈
사이킷런의 mokdel_selection 모듈은 학습데이터와 테스트 데이터 세트를 분리하거나 교차검증 분할 및 평가, 그리고 Estimator의 하이퍼 파라미터를 튜닝하기 위한 다양한 함수와 클래스를 제공합니다. 앞서 붓꽃 데이터 세트 분류시 사용했던 train_test_split()를 살펴봅니다.
3-1 train_test_split() - 학습/테스트 세트 데이터 분리
앞에서 수행한 예제와 같이 학습데이터와 테스트 데이터 세트를 train_test_split()로 분리 할 수 있습니다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
dt_clf = DecisionTreeClassifier()
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.3, random_state=121)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
print('예측 정확도 : {0:.4f}'.format(accuracy_score(y_test, pred)))
150개의 데이터 세트 중에서 30%, 45개의 테스트 데이터로 학습해 예측 합니다. 데이터 양도 양이지만 학습된 모델에 대해 다양한 데이터를 기반으로 예측 성능을 평가해보는 것도 중요합니다. 해당 예제에 몇번을 실행해봐도 예측 정확도는 동일합니다.
3-2 교차검증
위의 train_test_split()을 이용하면 예측정확도의 신뢰도가 좋지 못합니다.
고정된 학습 데이터와 테스트 데이터로 평가하다 보면 테스트 데이터에 최적의 성능을 발휘할 수 있도록 편향되게 모델을 유도하는 경향이 발생한다고 합니다. 이렇게 되면 다른 테스트용 데이터가 들어오게 되면 성능이 저하가 됩니다.
이런 문제점을 개선하기 위해 교차 검증을 이용해 더 다양한 학습과 평가를 수행합니다.
✔ 대부분의 머신러닝 모델의 성능평가는 교차 검증 기반으로 1차 평가를 한 뒤에 최종적으로 테스트 데이터 세트에 적용해 평가하는 프로세스 입니다.
3-2-1. K 폴드 교차검증
K폴드 교차검증은 K개의 데이터 폴드 세트를 만들어서 K번 만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법입니다.
예제로 풀어봅시다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
iris = load_iris()
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier()
#5개의 폴더 세트로 분리하는 KFold 객체 폴드 세트별 정확도를 담을 리스트 객체 생성
kfold = KFold(n_splits=5)
cv_accuracy =[]
print('붓꽃데이터 세트 크기', features.shape[0])
model_selection의 KFlod를 import 해 줍니다.
그리고 kfold 라는 KFold 객체를 만들어 주는데 인자 값으로 n_splits 에 5를 넣어줍니다.
5개의 예측 평가를 진행할 예정입니다. 붓꽃 데이터는 150개이므로 30개씩 5개로 나눠지겠네요.
for train_index, test_index in kfold.split(features):
print('train: ',train_index)
print('test : ',test_index)
print('###########'*3)
뒤이어 for문을 통해서 진행 할텐데 예제 진행 간 kfold.split(features)에서 어떤 값을 반영할지 궁금해서 한번 수행해 봤습니다. 앞어 kfold에는 5개(K개)의 학습/검증용 데이터세트가 들어간다고 입력 해줬어요. 결론적으로 kfold.split(features)는 입력받은 features를 5개의 데이터세트로 분할해서 이 중 4/5인 120개는 학습용 데이터 세트, 1/5인 30개는 검증용 데이터 세트로 분할하는데 이때 분할 할 수 있는 인덱스 값을 반환해줍니다.
n_iter = 0
#KFold 객체의 split()를 호출하면 폴드 별 학습용, 검증용 테스트의 로우 인덱스를 array로 반환
for train_index, test_index in kfold.split(features):
#KFold.split()로 반환된 인덱스를 이용해 학습용, 검증용 테스트 데이터 추출
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
#학습, 예측
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
n_iter += 1
#반복할 때마다 정확도 측정
accuracy = np.round(accuracy_score(y_test, pred),4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n{0} 교차 검증 정확도 : {1}, 학습 데이터 크기: {2}, 검증 데이터 크기 : {3}'.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'. format(n_iter, test_index))
cv_accuracy.append(accuracy)
#개별 iteration별 정확도 합하여 평균 정확도 계산
print('\n## 평균 검증 정확도 : ', np.mean(cv_accuracy))

앞에서 확인했듯이 for문을 통해 train_index와 test_index 값에는 학습과 검증을 위해 분할된 인덱스 값이 반환되게 됩니다. 이 인덱스 값들을 받아서 for문 내에서 학습과 검증을 반복합니다. 역시 fit()과 predict()로 진행합니다.
각 출력값에서 교차 검증 정확도를 알 수 있고 4/5와 1/5로 잘 나눠진 데이터 세트의 크기도 확인 할 수 있습니다.
train_test_split()와 달리 검증 시 마다 검증 정확도가 달라지는 것을 알 수 있습니다.
3-2-1. Stratified K 폴드
Stratified K폴드는 불균형 분포도를 가진 레이블 (결정 클래스) 데이터 집합을 위한 K 폴드 방식입니다.
불균형한 분포도를 가진 레이블 데이터 집합은 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우는 것을 말합니다.
K 폴드에서는 학습데이터와 검증데이터의 레이블 데이터가 균일하다는 가정하에 K 개로 쪼개서 검증하는 방식이었는데요. Stratified K 폴드에서는 레이블 데이터가 균일하지 않을 때 필요한 검증을 도와줍니다.
책에서 예를 든 것과 같이 대출사기 문제로 예를 들어 대출 사기 여부를 판단하는 것이 레이블(사기:1, 정상:0)이라 생각했을때 대출 사기가 (레이블 값 = 1) 발생한 비율이 현저히 적어서 특정 학습데이터 또는 검증 데이터에 고르게 반영되지 않을 가능성이 높아요. 사기가 하나도 발생하지 않은 학습/검증 데이터가 존재 할 수 있으니까요. 이런 비율을 고려해서 Statified K 폴드는 K폴드가 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습 및 테스트에 제대로 분배하지 못하는 경우의 문제를 해결해 줍니다.
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import KFold
iris= load_iris()
iris_df = pd.DataFrame(data = iris.data, columns = iris.feature_names)
iris_df['label'] = iris.target
iris_df['label'].value_counts()

붓꽃 데이터를 데이터 프레임에 넣고 레이블을 추가해서 결정 데이터 컬럼을 만들어 줬습니다.
붓꽃의 품종 종류가 50개씩 3개가 골고루 설정되어 있어요
kfold = KFold(n_splits=3)
n_iter = 0
for train_index, test_index in kfold.split(iris_df):
n_iter += 1
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print('## 교차검증 : [0}', format(n_iter))
print('학습 레이블 데이터 분포 :\n', label_train.value_counts())
print('검증 레이블 데이터 분포 :\n', label_test.value_counts())
실행결과가 이렇게 나왔습니다. 학습데이터와 검증데이터 구분 되는 것을 확인 할 수가 있어요. 학습데이터에서 1,2 밖에 없으면 0을 학습할 수 없고 검증레이블은 0 밖에 없으므로 학습레이블은 절대 0을 예측하지 못합니다.
이런 경우 검증 데이터 세트를 분할하면 검증 예측 정확도는 0이 될 수 밖에 없습니다.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=3)
n_iter = 0
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter += 1
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print('## 교차검증 : [0}', format(n_iter))
print('학습 레이블 데이터 분포 :\n', label_train.value_counts())
print('검증 레이블 데이터 분포 :\n', label_test.value_counts())
사용방법은 K 폴드와 비슷하지만 split 메소드에 인자로 피처 데이터 셋 뿐만 아니라 레이블 데이터 세트도 반드시 필요합니다. 확인 후 진행하면 학습 레이블과 검증 레이블이 동일한 비율로 할당된 것을 볼 수 있습니다.
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import StratifiedKFold
iris = load_iris()
feature = iris.data
label = iris.target
df_clf = DecisionTreeClassifier(random_state = 156)
skfold = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skfold.split(feature, label):
X_train, X_test = feature[train_index], feature[test_index]
y_train, y_test = label[train_index], label[test_index]
df_clf.fit(X_train, y_train)
pred = df_clf.predict(X_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred),4)
train_size = X_train.shape[0]
test_size = X_test.shape[0]
print('\n#{0} 교차 검증 정확도 : {1}, 학습데이터 크기 : {2}, 검증 데이터 크기:{3}'.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스:{1}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
print('\n## 교차 검증별 정확도:', np.round(cv_accuracy,4))
print('## 평균 검증 정확도:', np.mean(cv_accuracy))
statified K 폴드를 이용해 처음부터 진행해 봅니다.
3개의 statified K폴드로 교차검증 진행해서 다음과 같은 값이 나옵니다.
statified K폴드의 경우 원본 데이터의 레이블 분포도 특성을 반영한 학습 및 검증 데이터 세트를 만들 수 있으므로 왜국된 레이블 데이터 세트에서는 반드시 statified K 폴드를 이용해 교차검증을 해야 한다고 합니다.