[파이썬/머신러닝] PANDAS(판다스) 기본 익히기-2

DataFrame, Series의 정렬 - sort_values()
titanic_sorted = titanic_df.sort_values(by=['Pclass','Name'], ascending = 'False')
titanic_sorted.head(3)

sort_values()를 통해서 정렬 합니다. 파라미터로 by, inplace, ascending을 이용합니다.
by는 어떤 컬럼을 정렬할지 inplace는 원본데이터도 정렬을 적용할지, ascending은 오름차순을 적용할지 설정할 수 있습니다. (inplace의 기본은 False, ascending의 기본은 True)
위 예제에서는 'Pclass'와 'Name' 컬럼을 기준으로 내림차순 정렬을 합니다. 원본데이터는 영향을 미치지 않습니다.
실습 하면서 확인 했는데, 컬럼명의 대소문자를 구분하기 때문에 'Pclass'를 'pclass'로 입력하면 실행되지 않습니다.
Aggregation 함수 적용
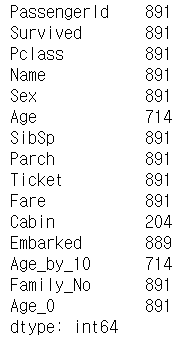
titanic_df.count()
titanic_df[['Age', 'Fare']].mean()

DataFrame에 min(), max(), sum(), count() 와 같은 aggregation 함수 적용을 할 수 있습니다. SQL과 유사합니다. DataFrame에서 바로 호출하면 모든 컬럼에 대한 Aggregation 함수를 적용합니다. 특정 컬럼들만 추출해 적용 할 수도 있습니다.
groupby() 적용
titanic_groupby = titanic_df.groupby('Pclass')[['PassengerId', 'Survived']].count()
titanic_groupby
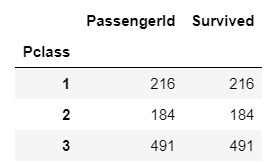
DataFrame에 groupby()를 적용하면 DataFrameGroupBy라는 또 다른 형태의 DataFrame을 반환합니다.
위 예제에서는 groupby()를 이용해 'Pclass'로 묶어 낸 다음 PassengerId, Survived 컬럼의 count를 보여준다.
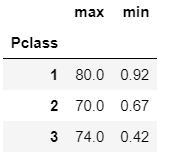
titanic_df.groupby('Pclass')['Age'].agg(['max', 'min'])
agg_format = {'Age' : 'max', 'SibSp': 'sum', 'Fare': 'mean'}
titanic_df.groupby('Pclass').agg(agg_format)
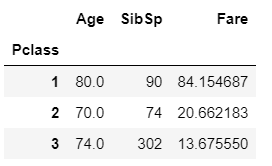
하나의 컬럼에 aggregation 함수를 적용할 때 agg()를 이용하여 인자로 설정 후 수행합니다.
여러개의 컬럼에 서로 다른 aggregation 함수를 적용 할 때 딕셔너리 형태로 aggregation이 적용될 컬럼과 aggregation 함수를 넣어 줍니다.
결손데이터 처리하기
titanic_df.isna().sum()
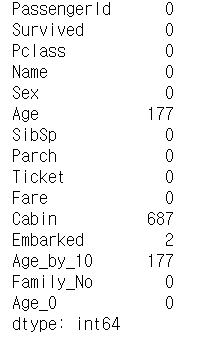
결손 데이터는 컬럼에 값이 없는, NULL인 가밧을 의미하는데 이를 넘파이에서는 NaN으로 표시합니다.. 기본적으로 머신러닝 알고리즘은 이 NaN 값을 처리하지 않으므로 이 값을 다른 값으로 대체해야 합니다.(NaN 값은 평균, 총합 등의 함수 연산 시 제외가 됩니다.)
NaN값은 isna()로 확인 가능합니다. 위 예제에서는 DataFrame내 NaN 값을 구하기 위해 isna()를 이용하고 나온 결과에 sum()을 이용해 개수를 구할 수 있습니다.(True는 1, False는 0)
위에서 확인 했을 때 NaN 값이 있는 컬럼은 Age, Cabin, Embarked, Age_by_10 컬럼입니다. 해당 컬럼의 NaN을 없애보겠습니다.
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
titanic_df['Age_by_10'] = titanic_df['Age_by_10'].fillna(titanic_df['Age'].mean()*10)
titanic_df.isna().sum()
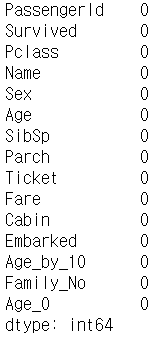
각 컬럼별 결손 데이터를 처리했습니다. 주의할 점은 위와 같이 반환값을 다시 받았다는 겁니다.
titanic_df['Age'], titanic_df['Embarked'], titanic_df['Age_by_10'] DataFrame에 각 각의 방식으로 NaN을 처리후 다시 해당 DataFrame으로 반환한 것을 확인 할 수 있습니다. 이렇게 하지 않으려면 fillna()내 파라미터에 'inplace=True' 를 넣어줘서 원본 데이터에 변경이 되게끔 설정해줘야 합니다.
'공부방 > 파이썬_머신러닝' 카테고리의 다른 글
| [파이썬/머신러닝] 사이킷런 기초다지기 - 3 (0) | 2020.11.09 |
|---|---|
| [파이썬/머신러닝] 사이킷런 기초 다지기 - 2 (0) | 2020.11.04 |
| [파이썬/머신러닝] 사이킷런 기초 다지기 - 1 (0) | 2020.11.03 |
| [파이썬/머신러닝] PANDAS(판다스) 기본 익히기-1 (0) | 2020.10.28 |
| [파이썬/머신러닝] NUMPY(넘파이) 기본 익히기 (0) | 2020.10.27 |



